CPU 的 Cache line 也可能成为限制多线程运行速度的一个因素
最近从好朋友那看到了两段有趣的代码
代码一:
#include <stdio.h>
#include <pthread.h>
struct {
long a, b;
} s;
void* thread_1(void *x) {
for (int i = 0; i < 99999999; ++i) {
s.a += 1;
s.b += 1;
}
}
int main(void) {
pthread_t t1;
pthread_create(&t1, NULL, thread_1, NULL);
pthread_join(t1, NULL);
printf("%ld %ld\n", s.a, s.b);
return 0;
}
代码二:
#include <stdio.h>
#include <pthread.h>
struct {
long a, b;
} s;
void* thread_1(void *x) {
for (int i = 0; i < 99999999; ++i) {
s.a += 1;
}
}
void* thread_2(void *x) {
for (int i = 0; i < 99999999; ++i) {
s.b += 1;
}
}
int main(void) {
pthread_t t1, t2;
pthread_create(&t1, NULL, thread_1, NULL);
pthread_create(&t2, NULL, thread_2, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
printf("%ld %ld\n", s.a, s.b);
return 0;
}
双线程对战单线程,结果如何?
乍一看,多线程版本的代码可以更高效地利用 CPU,每个线程操作的是不同的字段,也不存在临界区,应该就是它更快了吧!
可是,实际运行一下,结果却是:
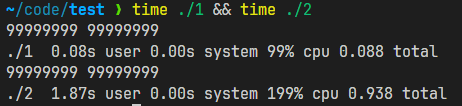
单线程更快,怎么回事呢?原来是CPU缓存的问题!现代多核CPU通常具有多级缓存,每个核都有自己的缓存。当多个线程同时访问共享的数据时,如果这些数据不在缓存中,就会导致缓存一致性的问题,需要不断地将数据从主内存加载到缓存中,以确保各个核之间的数据一致性。结果,运行速度就不如单线程快了。
如果想要解决,或许可以试试让它们不在一个 Cache line 中,避免缓存一致性的问题。
多线程,很神奇吧!